Great Lakes Bioinformatics Conference 2012
Travel
Leading Professional Society for Computational Biology and Bioinformatics
Connecting, Training, Empowering, Worldwide



November 24 - 28, 2025
Adelaide, Australia
Dec 10-13, 2025
Hong Kong, China
ISCB Official Event
December 6 - 8, 2025
Northeastern University, USA
Jan 3 - 7, 2026
Big Island, Hawai'i
April 21-22, 2026
Cambridge, UK
ISCB Official Event
May 26 - 29, 2026
Thessaloniki, Greece
May 27-29, 2026
Toronto, Ontario, Canada
ISCB Official Event
July 12 - 16, 2026
Washington, D.C., United States
ISCB Flagship Event
August 1 - September 9, 2026
Geneva, Switzerland
ISCB’s Annual Flagship Meeting
Support the society while achieving your marketing goals
Become a ISCB collaborative conference, learn more here
Regional, topical, worldwide - your platform to present science

dedicated to facilitating development for students and young researchers

The ISCB Affiliates program is designed to forge links between ISCB and regional non-profit membership groups, centers, institutes and networks that involve researchers from various institutions and/or organizations within a defined geographic region involved in the advancement of bioinformatics. Such groups have regular meetings either in person or online, and an organizing body in the form of a board of directors or steering committee. If you are interested in affiliating your regional membership group, center, institute or network with ISCB, please review these guidelines (.pdf) and send your exploratory questions to Diane E. Kovats, ISCB Chief Executive Officer (This email address is being protected from spambots. You need JavaScript enabled to view it.). For information about the Affilliates Committee click here.
Topically-focused collaborative communities

Connect with ISCB worldwide

Environmental Sustainability Effort

ISCB is committed to creating a safe, inclusive, and equal environment for everyone

Resource library for education and training materials

Search jobs, find talent

Science at the click of the mouse, recorded talks

High-quality research devoted to computer-assisted analysis of biological data

Latest research and publications

Certifying Quality in Computational Biology Education

Latest updates from ISCB
Highlighting Society events, programs, and achievements

Celebrating scientific achievement and innovation

Honoring our distinguished researchers

Recognizing contributions and achievements
Center for science, collaboration, and training
FASEB will provide two categories of MARC travel fellowships for the 2012 Great Lakes Bioinformatics Conference. Deadline April 3, 2012.
Please read the information at the FASEB website for eligibility.
FASEB Award Eligibility General Information Page: www.faseb.org/Marc/MARC-and-Professional-Development/Travel-Awards/Travel-Awards--Scientific-Meetings-and-Conferences.aspx
Faculty/Mentors and Students Travel Award: Each award provides funding for one faculty member/mentor and up to two students or post- baccalaureates from a minority institution to participate in one of the selected national meetings or conferences. The faculty/mentor must nominate up to two students and/or post-baccalaureates who are pursuing research careers in a life sciences discipline. The application packet must be submitted by the Faculty/Mentor listed on the application form. We do not accept Faculty/Mentor and Students Travel Award applications from students.
Poster/Platform (Oral) Presenter Travel Award: Each award provides funding for one underrepresented minority* graduate/ undergraduate student, post-baccalaureate or postdoctoral fellow who is 1st author and has been selected to give an oral or poster presentation at one of the selected national meetings or conferences.
[TOP]
 |
Howard Cash, President Gene Codes Corporation Gene Codes Forensics, Inc. Ann Arbor, MI - USA Biosketch (.pdf) Title: Designing Bioinformatics for the Wetware. Usability Challenges with Massive Amounts of Data. Abstract: Gene Codes Corporation began producing DNA sequencing tools that dominated the commercial market starting in the mid-1990s. Starting in 1997 and especially after 9/11, 2001, the company produced tools that completely changed the standard for DNA analysis software in forensic crime labs around the world. In neither case did success depend on new discoveries or dramatically more sensitive pattern detection algorithms. Instead, the Sequencher and M-FISys programs, respectively, raised the game on usability for the bench scientist. For people in bioinformatics, the changes in data scale have been dramatic over the last several years. How do we make that information available to the people who will benefit from it? If a consumer could truly get a full genome in a matter of seconds as portrayed in the dystopian movie, GATTACA, surely they would not want a listing of all of the individual data points. So where might bioinformatics professional focus in the future? We will briefly discuss where bioinformatics has come in the days since MolGen, UWGCG and IntelliGenetics and some of the principles that can help tool developers who focus on the data present that information so that end users can grasp its content. [TOP] [Return to Full Agenda Page] |
 |
Michael Lynch, Professor Department of Biology Indiana University Bloomington, IN - USA CV: www.bio.indiana.edu/faculty/directory/profile.php?person=milynch Title: Mutation, Drift, and the Evolution of Subcellular Features Abstract: Understanding the mechanisms of evolution and the degree to which phylogenetic generalities exist requires information on the rate at which mutations arise and their effects at the molecular and phenotypic levels. Although procuring such data has been technically challenging, high-throughput genomic sequencing is rapidly expanding our knowledge in this area. Most notably, information on spontaneous mutations, now available in a wide variety of organisms, implies an inverse scaling of the mutation rate (per nucleotide site) with the effective population size of a lineage. The argument will be made that this pattern naturally arises as natural selection pushes the mutation rate down to a lower limit set by the power of random genetic drift rather than by intrinsic molecular limitations on repair mechanisms. Additional support for this idea derives from the relative levels of efficiency of DNA polymerases and mismatch-repair enzymes in eukaryotes relative to prokaryotes. This drift-barrier hypothesis has general implications for all aspects of evolution, including the performance of enzymes and the stability of proteins. The fundamental assumption is that as molecular adaptations become more and more refined, the room for subsequent improvement becomes diminishingly small. If this hypothesis is correct, the population-genetic environment imposes a fundamental constraint on the level of perfection that can be achieved by any molecular adaptation. It also implies that effective neutrality is the expected outcome of natural selection, an idea first suggested by Hartl et al. in 1985. Although generally viewed as an independent process, mutation also operates as a weak selective force, thereby playing a central role in “nearly neutral” hypotheses in evolution. Most notably, genes and proteins with more complex structures are subject to higher rates of mutational degeneration simply because they are larger mutational targets. However, because the mutation rate is very low at the nucleotide level, the efficiency of such mutation-associated selection becomes of diminishing significance in populations with small effective sizes. Thus, mutationally hazardous genomic and gene-structural features, which may or may not be adaptive, are expected to passively arise in lineages with small effective sizes. This general principle, the mutational-hazard theory, will be illustrated with examples including: 1) the differential expansion of intron numbers in various phylogenetic lineages; and 2) the diversification of protein-architectural features. [TOP] [Return to Full Agenda Page] |
 |
Mercedes Pascual, Professor Department of Ecology and Evolutionary Biology Affiliate of the Center for Computational Medicine and Bioinformatics University of Michigan Ann Arbor, MI - USA CV: www.lsa.umich.edu/eeb/directory/faculty/pascual Title: Pathogen Diversity from an Ecological Perspective Abstract: Sequence data is becoming increasingly available for many pathogens in time and space. This presents the opportunity to describe their population structure at different scales and to address the role of this structure for epidemiology. In particular, the genetic diversity associated with antigenic phenotypes, the variation recognized by the immune system, is of interest. Here, conceptual models with a basis in competitive ecological interactions provide a basis to understand whether immune selection (competitive interactions between strains mediated by cross-immunity) structures pathogen populations and how this structure influences in turn the transmission dynamics of pathogens. In this talk, I present two examples from our work on Plasmodium falciparum malaria and H3N2 influenza respectively, with individual-based models of transmission that track the history of infection of individual hosts and the genetic relatedness of the pathogen. Empirical analyses and considerations on testing resulting predictions on this ‘strain theory’ are discussed. [TOP] [Return to Full Agenda Page] |
 |
Russell Schwartz, Professor Department of Biological Sciences and Lane Center for Computational Biology Carnegie Mellon University Pittsburgh, PA - USA CV: www.cmu.edu/bio/faculty/schwartz.html Title: Learning Population Histories from Genome Variation Data Abstract: High throughput sequencing technologies have made it possible to assemble vast libraries of genetic variation data describing how genomes differ from one person to another. Such data implicitly encode a history of our species at a population level due to the gradual accumulation of mutations in our genomes as we have developed from an initial founder population to the many diverse subpopulations that comprise our species today. Better characterizing this history could be useful not only to basic research but also to important practical problems in improving the effectiveness of genotype/phenotype association studies and better understanding how we have adapted to historical disease threats or environmental changes. Reconstructing this population history from the indirect evidence of random mutations is a challenging computational problem, but also an interesting problem from a computational biologist’s perspective because of a long history of different approaches reflecting different biological perspectives and drawing on different classes of computational methods. In this talk, we will examine new strategies for characterizing population history that attempt to synthesize some of these different perspectives into a more complete model of our history as a species. This work seeks to combine discrete algorithms and operation research methods arising from the field of phylogenetics with machine learning and statistical sampling methods arising from statistical genetic models of population substructure. We will examine the motivation behind these approaches and explore their development from a computational perspective. We will then see what we can learn by applying such methods to real data. In the process, we will see some of the many ways diverse computing paradigms can contribute to current research in human genetics. [TOP] [Return to Full Agenda Page] |
General Information:
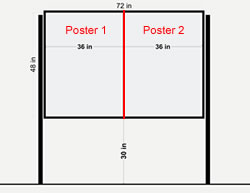
Schedule:
| DAY/DATE: | TIME: | ACTIVITY/LOCATION |
| Tuesday: May 15, 2012 | 2:00 pm to 4:00 pm | POSTER SESSION A PRESENTERS SET UP POSTERS (MAXIMUM poster dimensions are 46 inches high x 35 inches wide) |
| Tuesday: May 15, 2012 | 5:30pm to 7:30pm | POSTER SESSION A (authors present) See above for location Session A Presenters please remove your posters following the session so Session B presenters may set up |
| Wednesday: May 16, 2012 | 9:00 am to 4:00 pm | POSTER SESSION B PRESENTERS SET UP POSTERS (MAXIMUM poster dimensions are 46 inches high x 35 inches wide) |
| Wednesday: May 16, 2012 | 5:15pm to 7:15pm | POSTER SESSION B (authors present) See above for location (Authors please remove posters from boards at end of session) |
FURTHER QUESTIONS
GLBIO Conference Coordinator
Stephanie Hagstrom
This email address is being protected from spambots. You need JavaScript enabled to view it.
352-665-1763
[TOP]
Call for submissions of Poster Abstracts is now closed.
| KEY DATES | |
| March 15, 2012 | Call for Poster Abstracts |
| March 22, 2012 | Acceptance Notification for Poster Abstracts |
| May 4, 2012 | Registration Deadline for Poster Presenters |
Poster abstracts are solicited in all areas that involve the application of advanced computational methods to significant problems in biology or medicine.
Solicited Topic Areas:
• Algorithm Development and Machine Learning
• Bioimaging
• Databases and Ontologies
• Disease Models and Epidemiology
• Evolution and Comparative Genomics
• Gene Regulation and Transcriptomics
• Mass Spectrometry and Proteomics
• Metagenomics
• Population Genomics
• Protein Interactions and Molecular Networks
• Protein Structure and Function
• Sequence Analysis
• Text Mining
How to Submit:
Participants interested in presenting a poster at GLBIO are required to submit a 250-word abstract and scientific justification (why this work fits with the GLBIO community). Accepted abstracts will be printed on the conference website.
Conference Proceedings
Poster Presentations will NOT be considered for publication as part of the conference proceedings, only oral presentations.
Conference Registration
GLBIO conference registration for accepted oral and poster presenters must be completed by May 4, 2012 to remain eligible to present at GLBIO. Payment of the conference registration fee is the responsibility of the presenter.
>>CLICK HERE<< for the online submissions of poster abstracts.

ISCB Members enjoy discounts on conference registration (up to $150), journal subscriptions, book (25% off), and job center postings (free).

Connecting, Collaborating, Training, the Lifeblood of Science. ISCB, the professional society for computational biology!

Giving never felt so good! Considering donating today.
![]()
