The ISCB Affiliates program is designed to forge links between ISCB and regional non-profit membership groups, centers, institutes and networks that involve researchers from various institutions and/or organizations within a defined geographic region involved in the advancement of bioinformatics. Such groups have regular meetings either in person or online, and an organizing body in the form of a board of directors or steering committee. If you are interested in affiliating your regional membership group, center, institute or network with ISCB, please review these guidelines (.pdf) and send your exploratory questions to Diane E. Kovats, ISCB Chief Executive Officer (This email address is being protected from spambots. You need JavaScript enabled to view it.). For information about the Affilliates Committee click here.
The vision of the International Society for Computational Biology (ISCB) is to lead the field of computational biology to advance science and all of society. Our mission involves advocating for and advancing scholarship, research, training, outreach, and community building in computational biology for all. In pursuit of these goals, ISCB is governed by the principles of scientific excellence, integrity, professionalism, transparency, and collaboration.
ISCB affirms neutrality concerning socio-political events and issues that are not inherent to our core mission. Through its actions as an organization and those of its officers representing it, ISCB does not take positions on nor does it comment on these events and issues. Governed by the above principles, ISCB’s strength lies in uniting individuals from all backgrounds under the common pursuit of advancing the field of computational biology.
All talks will presented live regardless if you are participating in-person or virtually. While most presenters will be in-person, those unable to travel will be presented live through the conference platform and streamed into the venue presentation room.
As you plan your participation as a presenter please find below details to assist you with your specific presentation type at the conference:
log in to the virtual platform (https://iscb.junolive.co/) using the email you used when you registered
It is important that you use the same email as permissions on the virtual site are tied to your email
Once logged in navigate to your talk
There are multiple paths to your talk, for example searching through the Scientific Programme or via your profile page
Normally clicking on your talk will bring up the details about your talk. 30 minutes before the session where your talk is scheduled, that link will instead take you to the video conferencing system. This is why the email permissions are important.
We ask that you join as early as you are able within the 30 minute window to provide ample time to troubleshoot any issues that may arise. Please note, this is 30 minutes before the session containing your talk, not 30 minutes before your talk
If you need assistance joining the room there is a help chat available that will attempt to troubleshoot and connect you to live assistance. You can also contact This email address is being protected from spambots. You need JavaScript enabled to view it.
In-person Talk Details
For those presenting in-person, please note you mustuse the supplied computer due to the connection process with the JUNO virtual platform. You should pre-load your presentation on the in-room computer prior to the session in which you are scheduled to give your presentation.
Presentation Specifications:
All laptops will run Microsoft Windows 10 and include PowerPoint and Adobe. Powerpoint is the preferred presentation format.
PowerPoint 365 includes a subtitle generation feature improving accessibility of presentations and recordings for those hard of hearing
PDFs will not be able to have the full screen shown on the podium computers
If you need to convert your PDF to a PowerPoint, Adobe offers this free tool
All laptops will have Microsoft Office 365, compatible with the version from 2016. There should be no compatibility issues for presentations created with PowerPoint 2019 or 2021
If video will be a part of your presentation, it is highly recommended for it to be inserted using the “Video on my PC” option within PowerPoint
Save/include the video file included in the same folder as your presentation
It is not recommended to use the “Online Video” option
Presentation times will notbe extended for troubleshooting technical difficulties for videos that do not load
Custom/non-standard Windows fonts are not recommended or supported, if utilized ensure that the font(s) are fully embedded within your presentation file
Apple Keynote and Google Slides are not supported
Slide size should be set to “Widescreen (16:9)” within PowerPoint (this is the default)
Projector Information: 16:9 Aspect Ratio/1920x1080 resolution. Screen size will vary depending upon the room.
Live Talks and Pre-recorded Videos for the Content Library
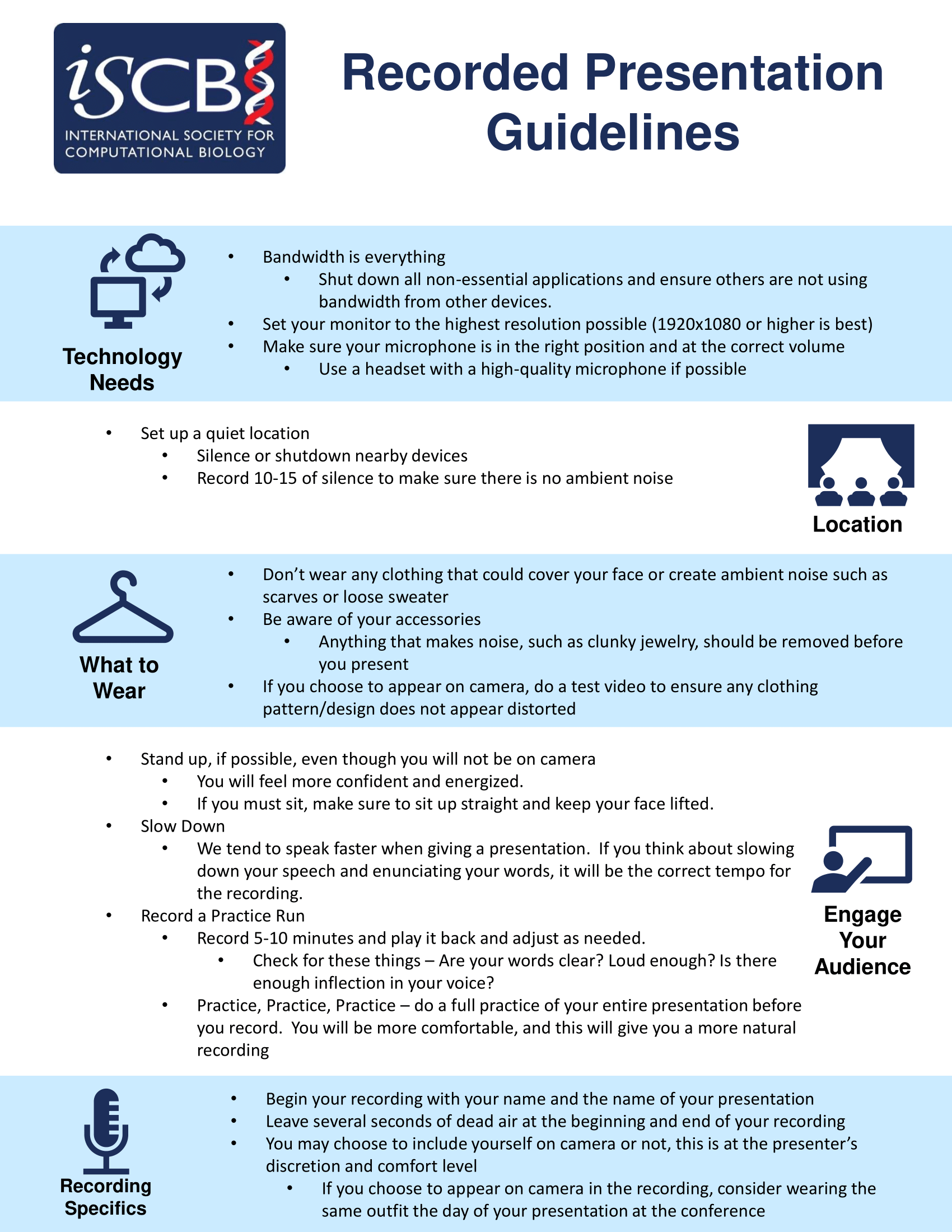
All abstract presenters, invited speakers, and proceedings presenters who are presenting virtually are required to provide a pre-recorded talk in advance of the conference. The pre-recorded talk will be used should circumstances prevent the virtual presenter from presenting live. This pre-recorded talk will be made available at the end of the day on which it is scheduled along with the session recordings.
Pre-recorded talks for the platform library should be an .mp4 file. Videos should be recorded in 720p - 1080p and there is no limit on video file size. Poster PDFs must not exceed 10Mb. Presenters will upload their recordings directly through the conference platform site after logging in as a registrant.
PLEASE note once submitted your video cannot be updated, though it can be removed and replaced.
Save your presentation as .mp4 file
Ensure you use the filename(s) provided to you in the email sent upon submission of the Confirmation of Participation. This email will be sent from This email address is being protected from spambots. You need JavaScript enabled to view it., be sure it is whitelisted so as not to miss any communications from ISCB
If a poster is being presented on the same material as a talk you must prepare a second video for the poster as the allowed time is shorter (5-7 minutes). The video for your talk cannot be used for your poster presentation. See the poster instructions below for more details
Recording may or may not include the presenter in the recording, this is at the presenter's discretion. Should the presenter elect to appear on camera in your recording, we suggest you wear the same outfit the day of your presentation.
Ensure you prepare your talk based on the length of time specified within the acceptance notification :
The following links can be of assistance for planning your presentation(s):
We suggest that if you are including a visual image of yourself in the recording you should be wearing the same outfit for the live Q&A. Turn on live captions using the Google Chrome browser. Download Chrome here if you haven’t already. Remember, you’ll always need to access the event website in Chrome for these captions to work. More details can be found at https://help.junolive.com/attendees/turn-on-live-captions
Poster Presentations
We require that in-person presenters upload, at minimum, a pdf or an mp4, but prefer you upload both so that our virtual attendees get the most from your work. This also serves to extend the life of your work so that all attendees are able to watch it on-demand after the conference. Virtual presenters are required to upload both.
Failure to upload a digital version of your poster will revoke your in-person poster acceptance. The following files can be uploaded
PDF of your poster must be no larger than 10Mb
Poster image as your cover image to replace the stock image (Optional, but high recommended)
Some helpful tips on planning your recorded talk are available below.
Presenting your poster in a lighting style format using the PechaKucha or Ignite talks presentation style or a single slide or PDF is an option for presenters.
Poster size limits can vary between conferences. Be sure to check the Posters page of the conference you're attending, found under the Programme & Agenda section, to confirm the size limits of your poster. Only in-person presenters need to print a poster.
For the best experience please consider the following in preparation of the conference:
Preferred browser is Chrome
Hardwire your computer vs wifi
Turnoff other browsers, background programs, and eliminate other internet devices being used if possible
Uploading your Talk
In person talk presenters are not required to upload anything to the virtual platform. They will upload their slides to the podium computer during a break before they present.
For virtual talk presenters, a pre-recorded mp4 of your talk is required as a back-up precaution should anything prevent you from being able to present live. We would rather play your recorded talk then have "dead time" within the programme. To ensure all required presentation materials are available, be sure to follow these steps to upload your files
You will be sent a "You have been added as an Admin" email from This email address is being protected from spambots. You need JavaScript enabled to view it. once the window for you to upload your talk opens
Additionally, you'll receive a notification on in your profile on the conference site that will direct you to the same location as the email
Click "Login" on the top right
Have a magic link sent to the email you used when you registering. Logging in with a password is only an option if you have configured a password in the virtual platform. Juno is a third party and your ISCB login credentials have not been shared
Navigate to your presentation. You can do so with the link in the "You have been added as an Admin" email, or you can navigate to your talk using the "Scientific Programme" on the virtual platform
Once on the page for your talk you will need to scroll down to click on your name, then "visit page" to go to your speaker profile
Click the "edit" button on your speaker profile
Use this page to add a photo and speaker bio (OPTIONAL) and be sure to click the "Save Changes" button after any updates
To upload your mp4, navigate to the "Meta Data" tab
Click the "Add Meta Data" button
Select "Upload MP4" from the type menu
Click "Choose a file" then navigate to the video on your computer
Be sure to use the filename provided upon submission of the Confirmation of Participation as using the incorrect filename may result in the file not being properly displayed
Confirm you have the right video and a pop-up will appear showing you progress of the upload
Once completed the "Cancel" button will change to "OK"
Click "OK" to close the pop-up
Scroll to the top of the page and click the "Save Changes" button
The following video tutorial from ISMB 2022 will walk you through the same steps
Uploading your Poster
A complete virtual poster consists of a 5-7 minute mp4 of the poster presentation to stream online, a pdf of the poster for download, and a jpg/png thumbnail image to identify the poster in the Virtual Poster Theater. The poster title, abstract, and presenter will have been uploaded to your poster page for you. We require that in-person presenters upload either the pdf or the mp4, but prefer you upload both so that our virtual attendees get the most from your work. This also serves to extend the life of your work so that all attendees are able to watch it on-demand after the conference. Virtual presenters are required to upload both the mp4 and the pdf.
Failure to upload a digital version of your poster will revoke your in-person poster acceptance. To ensure all required presentation materials are available be sure to follow these steps to upload your files
Additionally, you'll receive a notification on in your profile on the conference site that will direct you to the same location as the email
Click "Login" on the top right
Have a magic link sent to the email you used when you registering. Logging in with a password is only an option if you have configured a password in the virtual platform. Juno is a third party and your ISCB login credentials have not been shared
Navigate to your presentation. You can do so with the link in the "You have been added as an Admin" email, or you can navigate to your poster using the "Virtual Poster Theatre" on the virtual platform
Scroll down and click the "Edit" button. It is found above the "Analytics" stats and the various "log" buttons. Look for a cog above the word "Edit" within a coloured circle. Information about your poster is spread across the following tabs on the editing page
Information - This is where the bulk of the public facing information about your poster is kept.
Most of the fields will be pre-loaded with information provided in the CoP, these fields can be left unedited
Scroll down to the Images section, the leftmost item is Icon - this image will be used as the thumbnail for your poster in the Virtual Poster Theatre. To upload your thumbnail:
Click the box that says "Click or Drag to add Image"
Find and select the image on your computer, then click open
Scroll to the top of the page and click the "Save Changes" button
Rotators - this is where you'll upload the mp4 of your presentation. The steps to do so are:
Click "Add rotator"
Give the rotator a title
Type - use the drop down to find "Video Upload mp4"
Upload file - this will open a window to search your computer for the file
Be sure to use the filename provided upon submission of the Confirmation of Participation as using the incorrect filename may result in the file not being properly displayed
Click "Save Changes" and "CONFRIM" to begin the upload
Once uploading, don't navigate to another page - you may use a separate tab while the video is uploading
Once completed, the "CANCEL" button will update to "OK"
Click "OK" to close the upload tracker pop-up
Scroll to the top of the page and click "Save Changes"
Resources - this is where you'll upload the pdf of your presentation. This process is similar to that of the mp4
Click "Add Resource" to open the resource pop-up
Add a title (required)
Description is optional and not shown on the site
Upload your file using "Upload File"
This will allow you to search your local computer for the file you'd like to upload
Be sure to use the filename provided upon submission of the Confirmation of Participation as using the incorrect filename may result in the file not being properly displayed
File must be less than 10 MB - this limit only applies to the pdf
Once uploading, don't navigate to another page - you may use a separate tab while the pdf is uploading
Once completed, the "CANCEL" button will update to "Complete"
Click "Complete" to close the upload tracker pop-up
Upload the thumbnail you used above to the Image section
Click "Save Changes" to close the resource pop-up
Scroll to the top of the page and click "Save Changes"
Meta Data - this is where you may add in any personal links/ways to contact you. These are optional
Greeting - This will populate next to the rotator on the poster page. This is optional.
DO NOT EDIT THE INFORMATION ON THE FOLLOWING TABS: Representatives, Questions, Sessions, and Analytics
The following video tutorial from ISMB/ECCB 2023 will walk you through the same steps
The power of mobile communications has increased dramatically in recent years such that these devices (smartphone or tablet computer) can be used productively to do science [1]. The software applications installed on them do not necessarily have to be specialized to be useful for science, e.g., Evernote can be used as an electronic lab notebook [2]. Twitter is a popular microblogging platform famously limited to messages of up to 140 characters [3] and represents a simple way to express what's on your mind to a global audience of followers. Twitter has useful real-world scientific applications, such as in disease surveillance enabling the tracking of disease pandemics [4]–[6], as well as the capacity to be used for the communication of science itself [7]. Like other professionals, scientists are increasingly tweeting about their own research and the work of colleagues and sharing links to scholarly publications, laboratory results, and related scientific content such as molecular structures [8]. Twitter can additionally serve as a catalyst in the development of scientific tools, with at least one mobile app for science coming directly out of a tweet at a scientific conference [9].
If he or she is fortunate, a scientist may attend one or more scientific conferences in a year. In some fields, the number of conferences to attend is overwhelming. The time and cost expenditures required to physically participate in conferences necessitate an alternative route to access the information presented and capture it for future reference. Ideally, it would be preferable to monitor conferences remotely and at minimal or no cost. Increasingly, some scientists are using Twitter as a vehicle to summarize presentations and posters at conferences in real time, which is defined as “live tweeting.” The advantage of remote participation is that the information tweeted is open and free to anyone around the globe. From our own experiences of attending and live tweeting at several conferences over the past three years, the success of live tweeting appears dependent on the engagement of conference organizers with Twitter and its active encouragement before, during, and after the meeting. Surprisingly few conferences are actively encouraging scientists to tweet. This reticence is probably more likely due to ignorance of the potential rather than the possibility of loss of attendee revenue. We suggest that conference live tweeting is an opportunity to reach beyond those in the room while enabling feedback from those outside. Obviously, it is also in the best interests of conference organizers to provide free Wi-Fi so that international attendees do not have to use their expensive data plans and because the phone signal in many conference venues is generally weak. Crucially, the success of live tweeting depends on the ability of scientists to relay the highlights of a talk or to string together multiple tweets such that they can also be read as a contiguous narrative using tools such as Storify [10]. Some simple steps to enable the wider use of live tweeting at conferences may not be widely known to scientists.
For example, conferences like “Science Online” (#scioX, in which the # is a hashtag, the keyword-tagging system of Twitter that enables retrieval of all tweets about this conference) (Box 1) are at one extreme as an “unconference” [11], with multiple vibrant discussions happening during the sessions via Twitter. These discussions extend beyond the actual physical attendees, creating a parallel virtual meeting. Live tweeting is therefore a powerful tool for expanding scientific discourse to those not fortunate enough to attend a conference in person. Similarly, if a meeting has parallel sessions, tweeting then enables conference attendees or virtual conference attendees to listen in on multiple talks simultaneously. These conferences do not have to be limited to academic gatherings and may extend to those that are organized by commercial entities, which are generally more expensive to attend and very specialized. Often useful discussions happen between talks in casual environments, and tweeting those observations or conversations is probably acceptable with the agreement of both parties, unless these are private, off-the-record discussions.
Box 1. Common Twitter Abbreviations
# = hashtag @ = nametag, a way to reply to someone .@ = broadcast a tweet that begins with a nametag RT = retweet, share something already tweeted HT = hat tip, acknowledge or thank a source DM = direct message CX = correction Tweetup = physical meeting of tweeters
At the other extreme, which unfortunately is representative of most scientific conferences we have attended, there are few if any active live tweeters. This could be for several reasons: demographics of attendees, esoteric subject matter, and whether the organizer wants information to extend outside the conference halls (Gordon Conferences is one organization that may discourage tweeting on the assumption that this prevents scientists from sharing unpublished data). Sometimes the organizers of these conferences either do not actively encourage tweeting or they choose a cumbersome hashtag (Box 1) that consumes precious characters without signaling what the conference is even about (e.g., the Lysosomal Disease Network's #world_symposium, the annual conference on lysosomal storage diseases [12], which we shortened to #LDN14). Others have provided general recommendations for tweeting at academic conferences, such as rules of thumb [13], [14], dos and don'ts [15], and the types of tweets that can be useful [16]. However, we are not aware of concise efforts to describe live tweeting at science conferences other than a vaguely informative “how to tweet at conferences” [17]. An exhaustive perspective on live coverage at scientific conferences using web technologies has been described at length and focuses on bloggers in general [18], but this does not go into detail on how to use Twitter at these conferences specifically. This is important because the types of information tweeted could also be useful to followers in different spheres, such as patients, disease advocates, financial analysts, and pharmaceutical and biotech companies.
Scientists in some cases tend to be quite introverted (varying by field) so any efforts to break the ice or engage new participants at conferences are also welcome. Twitter can play an active role here to bridge or break down the gap between researcher cliques and can serve as a means to introduce you and your ideas to others in the field, without having to personally “know” them. We have found from our own experiences that Twitter interactions that initially formed online during the meeting or previous meetings can have a lasting presence in real life, forging collaborations and further expanding on discussions initiated via Twitter.
In light of those observations, it's worth proposing ten simple guidelines to encourage conference organizers, conference attendees, and anyone interested who uses Twitter to enhance the spread of scientific information beyond the physical walls of the auditoria in which meetings are held. While it is possible to add many other recommendations (such as encouraging the use of Storify to combine tweets from a meeting), we believe this is a good starting point for scientists new to Twitter and perhaps previously unwilling or unable to live tweet. While we would not claim to be the absolute authorities on Twitter use at conferences, our cumulative experiences of live tweeting have enabled us to provide a short list of recommendations. These ten simple rules are certainly ripe for future refinement or replacement as other microblogging tools are developed. Of course, it's also important to remember to enjoy the conference (if you are attending in person) and please try to add some local color to the proceedings in your tweets by describing the conference locale (using pictures if permitted). Don't be afraid to add personality while providing a voice for those not physically attending.
In the style of Twitter, we have kept these “rules or recommendations” to a maximum of 140 characters (so that they can in turn be tweeted).
Rule 1: Short Conference Hashtag
As soon as the meeting is announced, conference organizers should claim a short (6–8 characters) descriptive # that includes the year.
Rule 2: Promote the Hashtag
Highlight the hashtag in all conference materials online, in print, on name badges, and on Twitter if possible.
Rule 3: Encourage Tweeting
Encourage live tweeting at the conference. Session chairs can facilitate this and relay questions from the twitterosphere.
Rule 4: Conference Twitter Etiquette
Keep questions short and on the science, avoid grandstanding, encourage responsible tweeting, and avoid harassment or snarkiness.
Rule 5: Conference Tweet Layout
List speaker name, affiliation and conference hashtag in the first tweet; surname or initials and meeting hashtag are sufficient thereafter.
Rule 6: Keep Conference Discussion Flowing
Summarize presentations concisely, use hashtags for keywords, and use “@ reply” to engage individuals who can add to the discussion.
Rule 7: Differentiate Your Opinions from the Speaker's
Separate your own comments/viewpoints on the speaker or science being described in a presentation from the speaker's own words.
Rule 8: Bring Questions up from Outside
Check for and raise questions from those outside the conference, returning the speaker responses to positively enforce participation.
Rule 9: Meet Other Live Tweeters Face to Face
Organize tweetups so that conference attendees can meet in person and consolidate relationships and collaborations.
Rule 10: Emphasize Impact of Live Tweeting
Ensure that positive effects of tweeting at conferences, such as discoveries, publications, or collaborations, are highlighted.
Acknowledgments
Dr. Neil Dufton is gratefully acknowledged for creating the figure.
References
Williams AJ, Ekins S, Clark AM, Jack JJ, Apodaca RL (2011) Mobile apps for chemistry in the world of drug discovery. Drug Disc Today 16: 928–939.
Walsh E, Cho I (2013) Using Evernote as an electronic lab notebook in a translational science laboratory. J Lab Autom 18: 229–234.
Anon (2014) Twitter. Available: https://twitter.com/. Accessed 14 July 2014.
Chew C, Eysenbach G (2010) Pandemics in the age of Twitter: content analysis of Tweets during the 2009 H1N1 outbreak. PLoS ONE 5: e14118.
Signorini A, Segre AM, Polgreen PM (2011) The use of Twitter to track levels of disease activity and public concern in the U.S. during the influenza A H1N1 pandemic. PLoS ONE 6: e19467.
Chunara R, Andrews JR, Brownstein JS (2012) Social and news media enable estimation of epidemiological patterns early in the 2010 Haitian cholera outbreak. Am J Trop Med Hyg 86: 39–45.
Ekins S, Clark AM, Williams AJ (2012) Open Drug Discovery Teams: A Chemistry Mobile App for Collaboration. Molecular Informatics 31: 585–597.
Ekins S, Clark AM, Williams AJ (2012) Open Drug Discovery Teams: A Chemistry Mobile App for Collaboration. Mol Inform 31: 585–597.
Ekins S, Clark AM, Williams AJ (2013) Incorporating Green Chemistry Concepts into Mobile Chemistry Applications and Their Potential Uses. ACS Sustain Chem Eng 1: 8–13.
Anon (2014) Storify. Available: https://storify.com/. Accessed 14 July 2014.
Anon (2014) Science Online. Available: http://scienceonline.com/. Accessed 14 July 2014.
Anon (2014) World Symposium. Available: http://lysosomaldiseasenetwork.org/. Accessed 14 July 2014.
Priego E (2012 October 3) Live-tweeting at academic conferences: 10 rules of thumb. Available: http://www.theguardian.com/higher-education-network/blog/2012/oct/03/ethics-live-tweeting-academic-conferences. Accessed 14 July 2014.
Croxall B (2014 January 6) Ten Tips for Tweeting at Conferences. Available: http://chronicle.com/blogs/profhacker/ten-tips-for-tweeting-at-conferences/54281. Accessed 14 July 2014.
Varin V (2013 March 5) The Dos and Don'ts of Live-Tweeting at an Academic Conference: An Update. Available: http://blog.historians.org/2013/03/the-dos-and-donts-of-live-tweeting-at-an-academic-conference-an-update/. Accessed 14 July 2014.
Long CP (2013 September 16) The art of live-tweeting. Available: http://www.cplong.org/2013/09/the-art-of-live-tweeting/. Accessed 14 July 2014.
Shiffman D (2012 January 17) How to live-tweet a conference: A guide for conference organizers and twitter users. Available: http://www.southernfriedscience.com/?p=12120. Accessed 14 July 2014.
Lister AL, Datta RS, Hofmann O, Krause R, Kuhn M, et al. (2010) Live coverage of scientific conferences using web technologies. PLoS Comput Biol 6: e1000563.
In recent years, large language models (LLMs) with billions of parameters have become increasingly adept at reading and generating text. These models are also beginning to have an important influence as tools for computational biology. With the emergence of freely available text generation tools, the International Society for Computational Biology (ISCB) has decided to create an acceptable use policy for these models. ISCB accepts that this is a fast-moving area of research and that this policy is likely to be subject to change.
The ISCB Acceptable Use of Large Language Models Policy is applied to all scientific research submissions for ISCB Conferences, as well as research submissions to the ISCB/OUP Bioinformatic Advances journal. OUP has also accepted the use of the policy for research submissions to OUP Bioinformatics journal.
ISCB strongly encourages its affiliated groups and affiliated conferences to apply the Policy to scientific research submissions for their individual conferences and journals.
Confidentiality
When using commercial LLMs. such as ChatGPT or Gemini, data may be reused and thus it is important that confidential or personal information is not shared. This is particularly important with respect to peer review. The NIH currently forbids the use of LLMs in peer review for this reason (see NIH policy). Many Institutions have also developed further policies that may apply.
Below we list the acceptable and unacceptable uses of LLMs and related technologies. Note that acceptable use cases only apply where confidentiality is not an issue.
Unacceptable Uses:
It is not acceptable to use LLMs or related technologies to draft paper sections. In essence, papers MUST be written by humans.
It is not acceptable to use LLMs or related technologies to carry out reviewing activities, such as scientific peer reviews and promotion and tenure reviews. Firstly, these are an important part of the scientific process and they require scientific judgement. Secondly, review processes are in general confidential and should not be shared with third parties, including commercial LLM providers.
LLMs cannot be listed as authors as they do not fulfill the requirements of authorship as laid out in the ICMJE guidelines.
Acceptable Uses:
As an algorithmic technique for research study in your research e.g. LLMs for protein structure prediction
As an aid to correct written text (spell checkers, grammar checkers)
As an aid to language translation, however, the human is responsible for the accuracy of the final text
As an evaluation technique (to assist in finding inconsistencies or other anomalies)
It is permissible to include LLM generated text snippets as examples in research papers where appropriate, but these MUST be clearly labeled and their use explained.
Assist in code writing, however, the human is responsible for the code.
Create documentation for code, however, the human is responsible for the correct documentation.
To discover background information on a topic, subject to verification from trusted sources.
The development of these models is changing rapidly and it is not easy to foresee how they may be adopted. Therefore, it is likely that these guidelines will be subject to change in the future. At present, we do not intend to systematically detect usage of these models, but we will investigate reported instances on a case-by-case basis.
The safety of conference participants is ISCB’s top priority. Participants should be aware that, while ISCB will make every effort to reduce health risks on-site, it is possible that attendees may come into contact with individuals who carry communicable diseases during travel or while attending the event. ISCB recommends that attendees follow public health guidelines and take precautions to protect themselves and others. ISCB believes the most effective way for participants to maximize their own safety is to take appropriate preventive measures, including vaccinations if eligible and able.
Participants of ISCB conferences understand that it is their responsibility to review and ensure compliance with any stated country guidelines both for entering the country and departing to return to their country of origin. Costs associated with travel are the responsibility of the participant.
For those unable to travel, those who do not meet health requirements, or those who choose not to travel due to health reasons, ISCB offers virtual meeting registration options.
Public health guidance on preventing the transmission of communicable diseases continues to evolve, and ISCB will base its on-site protocols on the latest guidance.
The wearing of protective masks is not required. Participants are welcome to bring and wear a mask if they choose. ISCB reserves the right to alter this protocol as appropriate at any time.
On-site participants must agree that if they become symptomatic, they will immediately cease in-person participation in the meeting and get tested for illness. Individuals who test positive for a communicable disease should not continue attending the meeting in-person until symptom free.
If a registered participant is unable to attend due to illness, ISCB will partially refund the registration fee, reducing it to the virtual registration fee. Full refund requests must be made prior to the start of the conference and accompanied by appropriate documentation.
Upon registration to the conference, ISCB will require all in-person participants to sign the following waiver:
I understand that travel and gathering involves risk of sickness, including communicable diseases. I waive and release ISCB and its sponsors and exhibitors, and their employees and agents, from and against claims, liabilities, and expenses arising from injury, sickness, or death from contraction or spread of communicable disease due to travel to or attendance at an event sponsored by ISCB.
I will take necessary precautions while at the event. I agree not to attend any ISCB event if I feel ill or have had recent exposure to a communicable disease case. This waiver and release is binding on me.
The International Society for Computational Biology, Inc. (ISCB) respects, and is committed to protecting, the privacy of its members and readers. This Privacy Statement describes the policy and practice for use of information collected online from the ISCB website (iscb.org), its affiliated websites, and all order forms and member services accessible from those sites. These sites may link to other websites over which, ISCB has no control and, therefore, is not responsible. Your use of ISCB websites constitutes your acceptance of this Privacy Statement. If you do not agree with all the terms in this Privacy Statement, you should not use ISCB websites or services.
Personal Information ISCB collects only information supplied by the user. On certain web pages, ISCB asks the user to enter personal information such as name, address, email address, telephone number, fax number, credit card number, and other information from which the user's identity is discernible. Examples include:
Membership renewal information
ISCB official conferences registration
ISCB donation and annual giving pages
Sponsorship and exhibiting forms
ISCB Career Center
When users contact ISCB by phone or email
ISCB uses credit card information only to process a payment.
Personal data collected by ISCB is: (a) processed lawfully, fairly and in a transparent manner in relation to the data subject; (b) collected for specified, explicit and legitimate purposes and not further processed in a manner that is incompatible with those purposes; (c) adequate, relevant and limited to what is necessary in relation to the purposes for which data are processed; (d) accurate and, where necessary, kept up to date; every reasonable step is taken to ensure that personal data that are inaccurate, having regard to the purposes for which they are processed, are erased or rectified without delay; (e) kept in a form which permits identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed or for which is provided consent by the user; personal data stored for longer periods insofar as the personal data will be processed solely for archiving purposes are safeguarded; (f) processed in a manner that ensures appropriate security of the personal data, including protection against unauthorized or unlawful processing and against accidental loss, destruction or damage, using appropriate technical or organizational measures.
Non-Personal Information ISCB also collects non-personal information such as:
Cookies. These are pieces of data placed on the user's hard drive for a variety of reasons, including authentication (for example, to track individual website views). Cookies are collected by third party vendors with whom ISCB contracts for services. Users may set browsers to alert them to the use of cookies and may reject the use of the cookie, but rejection may prevent the website from functioning properly.
IP addresses.
Web-beacons. These are objects embedded into a webpage or email, which allow ISCB to confirm that the user has viewed the webpage or the email.
ISCB does not sell or otherwise disclose the information it collects to third parties, except as follows:
If required to do so by law, or if requested/subpoenaed by law enforcement agencies.
Information may be disclosed to consultants for internal business purposes.
ISCB may sell its mailing list to parties who provide products or services of interest the community. Members who do not wish to have their information shared may opt-out of mailing in their member profiles.
ISCB reserves the right to transfer information in the event that another entity acquires portions of the activities conducted by ISCB. Should this occur, all reasonable efforts will be made to ensure the new entity follows a similar Privacy Policy to ISCB.
Steps ISCB Takes to Protect the Privacy of Information it Collects
ISCB implements reasonable technical and administrative practices to safeguard the information it collects. For example, ISCB server's are firewalled to help protect a breach of data. ISCB employees are trained on appropriate use of information and the need for confidentiality. In addition, credit card payments submitted online on web pages are secured by the appropriate software and verified by Authorize.net. Credit card numbers submitted online are not stored by ISCB.
To unsubscribe from email alerts from ISCB, click unsubscribe at the bottom of the email.
Request a copy of what is being stored by ISCB. Request processing times will apply.
Your use of ISCB websites constitutes your acceptance of this Privacy Statement. If you do not agree with all the terms in this Privacy Statement, you should not use ISCB websites or services.
ISCB reserves the right to make changes to this Privacy Statement at any time. These changes will be indicated by a change to the "Last Updated" date on the page. Your continued use of the sites after any change indicates your agreement with the altered Privacy Statement.
ISCB does not knowingly collect personal information from children under the age of 18. If ISCB learns that it has personally identifiable information about a child under the age of 18, this information will be deleted. If you are under the age of 18 and wish to register to obtain further information or be included in a survey, your parent or legal guardian must register for you.
The Articles of Incorporation of the International Society for Computational Biology (ISCB) state that the objective of the Society shall be to promote the development and application of computational methods to problems of biological significance. The mission of the Society is to advance understanding of living systems through computation and to communicate those scientific advances worldwide. These goals demand honesty and truthfulness in all activities sponsored or supported by the Society.
Science is best advanced when there is mutual trust, based upon honest behavior, throughout the community. Our scientific Society thus expects all our members to adhere to the highest standards of honesty and integrity in all their actions, whether inside or outside ISCB. Honesty must be regarded as the cornerstone of ethics in science. Professional integrity in the formulation, conduct, interaction, and reporting of bioinformatics and computational biology activities reflects not only on the reputation of individuals and their organizations, but also on the image and credibility of the profession as perceived by scientific colleagues, government and the public. It is important that the tradition of ethical and professional behavior be carefully maintained and transmitted with enthusiasm to future generations.
Each researcher, practitioner, technician, student, and supplier within the field is a citizen of the community of science. Each shares responsibility for the welfare of this community. The guiding principles set forth in this ISCB Code of Ethics and Professional Conduct are meant to protect the community of science. The guiding principles are not meant to address a complete list of all ethical issues but rather serve as a guide, updated by events and experience. Society members have an individual and a collective responsibility to ensure that there is no compromise with these guidelines.
Aim to uphold and advance the integrity and dignity of the profession and practice of bioinformatics and computational biology
Aspire to use their knowledge and skills for the advancement of life sciences and human welfare
Strive to increase the competence and prestige of the profession and practice of bioinformatics and computational biology by responsible action and by sharing the results of their research through academic and commercial endeavors, or by public service
Seek to maintain and expand their professional knowledge and skills. Respect professional Codes of Ethics and abide by the prevailing ethical and legal norms of their profession
Endeavor for objectivity in their professional activities through recognition, acknowledgment, and mitigation of intentional and unintentional biases
Adhere to the highest standards of publication ethics in line with those documented by the Committee on Publication Ethics. This includes but is not limited to: timely and accurate reporting of findings; full disclosure of author contributions, sources of financial support, and any potential conflicts of interest; fair and objective peer-review
Act responsibly, honestly, and respectfully toward colleagues, government, corporate sponsors, the wider health care community and the public at large. Build public trust through accountability
Foster fair participation of all people, including those of underrepresented groups in all of the Society’s activities and at all levels of its organization. Prejudicial discrimination on the basis of age, color, disability, ethnicity, family status, gender identity, labor union membership, military status, nationality, race, religion or belief, sex, sexual orientation, or any other inappropriate factor is an explicit violation of the Code. Harassment, including sexual harassment, bullying, and other abuses of power and authority, is a form of discrimination that, amongst other harms, limits fair access to the virtual and physical spaces where such harassment takes place.
Treat colleagues and researchers with respect and courtesy, based on principles of equality and mutual respect for those with differing worldviews, scientific perspectives, or from different cultures. Share research results and ideas honestly; engage in scientific critique and peer review with integrity and respect; give proper credit for others' contributions.
Maintain professional competence by advancing their knowledge and understanding of new scientific developments and emerging areas of practice through ongoing education and training
Educate employees, students, and professionals to follow responsible research practices consistent with the highest ethical standards. Treat trainees with respect and provide them with opportunities for professional growth and development
Share knowledge in research, practice, and ethics through publication, professional meetings and conferences, and foster collaborations. Meet applicable ethical and legal standards while collaborating
Engage in scientific critique and peer review with integrity and respect, ensuring that evaluations of research are conducted objectively and constructively. Focus criticism on the work itself and never involve personal attacks, defamation, belittlement, or slander of the researcher(s). Foster a culture where scholarly discourse advances science while upholding professionalism and dignity.
Foster public understanding of the nature and objectives of bioinformatics and computational biology consistent with open and responsible use of findings in science and health care
Strive for objectivity in their professional activities through recognition, acknowledgment, and mitigation of intentional and unintentional biases
Respect the confidential nature of all information and research data entrusted to them. Disclose information with proper and specific authority through the consent of the individual or where there is a legal, ethical or professional right or duty to disclose
Claim expertise only in areas where they have the necessary depth of knowledge, especially when contributing to public discussion or policy debate. Do not make statements that are false, deceptive, or fraudulent concerning research, practice, or other work activities, or those of persons or groups with whom they are affiliated. Present personal opinions as such and not as those of the Society
Disclose any potential conflicts of interest. Safeguard the quality and credibility of their professional judgment
Report science accurately, with an appropriate level of detail, without distortion. In critiquing the work of others, focus on the findings specifically and never involve personal attacks.
Refrain from demeaning, discriminatory, or harassing behavior, conduct and speech. Make ISCB and the community a place (virtually and in-person) that is welcoming and respectful to all participants, regardless of race, gender, gender identity, age, sexual orientation, disability, physical appearance, national origin, ethnicity, or religion. Examples of demeaning, discriminatory, or harassing behavior, conduct and speech are any action directed at an individual that:
interferes substantially with that person’s participation
causes that person to fear for his/her personal safety
involves personal attacks, defamation, belittlement, or slander of a researcher
This includes threats, intimidation, bullying, stalking, or any conduct that discriminates or denigrates an individual on the basis of race, ethnicity, religion, citizenship, nationality, age, sexual or gender
Demonstrate professionalism and collegiality in ISCB activities and communications, including committees, task forces, forums, social platforms, and events, at all times avoiding abusive, racist, sexist, harassing, defamation, belittlement, slander, or threatening speech and/or behavior towards any other individual.
The Code of Ethics and Professional Conduct applies to all participants of all ISCB related activities, including but not limited to:
Conferences, affiliated groups, communities of special interest (COSIs), workshops, and events sponsored, co-sponsored, or in cooperation with;
Exchanges among committees or other bodies associated with ISCB communication sent through ISCB communication channels and associated social media
Interactions online via social platforms and blogs; and
Communications of press/media pass holders who are communicating through their own blogs/communication platform while in attendance of ISCB events or activities
Our goal is to foster a culture that creates a safe and open working environment for all who are participating in ISCB activities, conferences, and programs. We value diversity of thought and inclusivity at our conferences. To maintain an inclusive environment, ISCB events do not permit activism, rallies, protesting, or the distribution of materials regarding partisan political, religious or other ideological views that are not directly related to our organization's mission and the event's focus areas during event hours or within event spaces.
While ISCB is not an adjudicating body, ISCB has appointed Ombudspersons who can be consulted, give advice or help seek out appropriate authorities to further handle any form of harassment or assault.
In matters directly related to alleged acts of misconduct as it relates to the ISCB Ethics and Professional Code of Conduct that take place within the purview of ISCB, ISCB is committed to listening to and addressing complaints and to guiding complainants through options confidentially before the complainant decides how to proceed. This includes ISCB consulting on details for potential informal solutions or a formal complaint. The ISCB Ombudspersons can be approached and if necessary outside counsel or consultation may be sought.
The ISCB Ethics and Professional Conduct Committee (EPC) serves primarily as an agency for conciliation, drawing on the experience and judgment of peers to uphold standards of reasonable, respectful professional behavior in computational biology.
Not a legal body: The EPC has no staff, legal expertise, or budget for judicial processes. Its only authority is the moral force of the community’s collective judgment.
Emphasis on professional standards: Most concerns involve nuanced situations. The EPC facilitates resolutions that protect the integrity and collegiality of our field.
Key Principles
Confidentiality: All proceedings are confidential to protect all parties. No retaliation: Retaliation for participation in this process is strictly prohibited. Encouraged settlements: Parties are encouraged to reach mutually acceptable solutions where feasible.
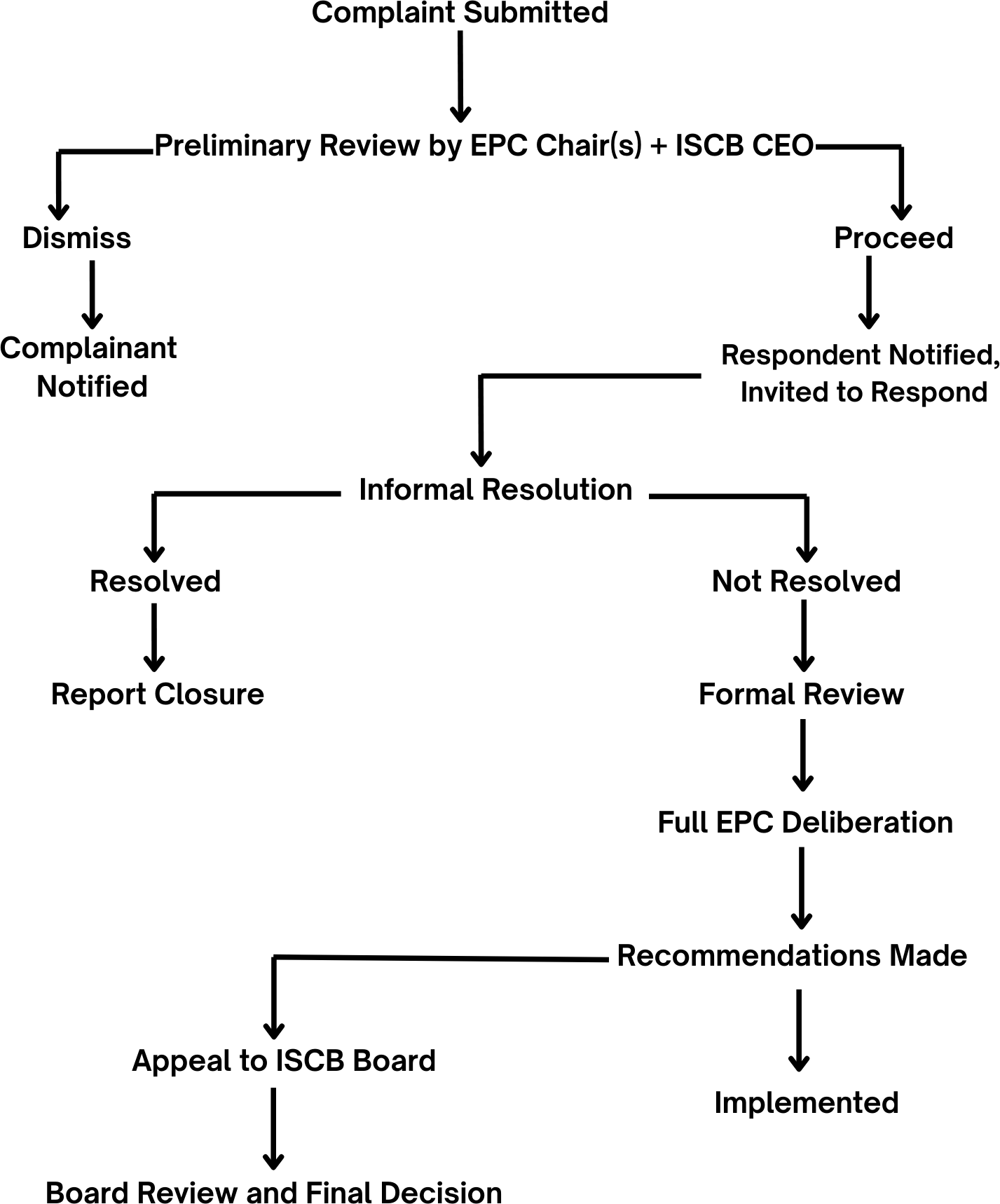
Complaint Resolution Path
Submission
Concerns can be raised by any ISCB member or participant in ISCB activities.
Complaints must include enough detail to assess.
Preliminary Review
The EPC Chair and Chief Executive Officer determine if the complaint:
Falls under EPC scope
Should be dismissed or move forward
Notification & Response
If the complaint is proceeding, the respondent is notified and invited to respond.
All parties are reminded to maintain confidentiality.
Informal Resolution (Most cases)
Facilitated dialogue or mediation seeks an equitable solution.
If resolved, the EPC simply reports that the matter was handled.
Formal Review (Rare cases)
For serious or unresolved issues:
Additional information may be gathered.
The full EPC deliberates and makes recommendations.
Recommendations
May include a statement of concern, referral to an institution, notification to the ISCB Board, or, rarely, a public notice.
Appeals
The respondent may appeal formal outcomes to the ISCB Board.
Contact & Records
All inquiries go through the EPC Chair(s) and/or ISCB Chief Executive Officer. The EPC maintains confidential records to inform future cases.
Legal counsel is accessed only through the ISCB Secretary or the ISCB Chief Executive Officer.
The EPC’s goal is to uphold professionalism, ensure fair treatment, and support an environment where science and careers can flourish.
ISCB collects basic information from you when you create an account, such as name, address, email address, organization and phone number. When registering for membership, you will also have the option to provide additional information such as highest degree, gender, career stage. During the registration process for both membership and conferences, you will also have the option to disclose your research areas and select to be part of our Communities of Special Interest. Within the Career Center, if you register to be part of the recruiting portal, you will be asked to upload a CV/resume. We also use cookies and similar technologies on our websites and mobile applications to collect information about interactions and usage. See the Privacy Policy for more details about the specific type of information we may collect and your choices related to that data.
We use information about you to deliver, improve, update and enhance the services we provide to you. For example, we use information about you to create your account, deliver our services related to the program for which you have registered (including websites and mobile applications), and to make sure we are delivering the top services to our members.
ISCB does not sell or otherwise disclose the information it collects to third parties, except as follows:
If required to do so by law, or if requested/subpoenaed by law enforcement agencies
Information may be disclosed to consultants for only internal business purposes
ISCB may sell its mailing list to parties who provide products or services of interest the community. Members who wish to have their information shared must opt-in to mailing in their member/user profiles. Members have the ability to opt-out at any time