Discover Prague
Looking to explore while visiting Prague? Visit http://www.prague.eu/en to learn more about the many sightseeing adventures that wait you.
Leading Professional Society for Computational Biology and Bioinformatics
Connecting, Training, Empowering, Worldwide







July 12 - 16, 2026
Washington, D.C., United States
ISCB Flagship Event
Dec 10-13, 2025
Hong Kong, China
ISCB Official Event
December 6 - 8, 2025
Northeastern University, USA
Jan 3 - 7, 2026
Big Island, Hawai'i
April 21-22, 2026
Cambridge, UK
ISCB Official Event
May 26 - 29, 2026
Thessaloniki, Greece
May 27-29, 2026
Toronto, Ontario, Canada
ISCB Official Event
August 31 - September 4, 2026
Geneva, Switzerland
Bioinformatics Community Events
ISCB’s Annual Flagship Meeting
Support the society while achieving your marketing goals
Become a ISCB collaborative conference, learn more here
Regional, topical, worldwide - your platform to present science

dedicated to facilitating development for students and young researchers

The ISCB Affiliates program is designed to forge links between ISCB and regional non-profit membership groups, centers, institutes and networks that involve researchers from various institutions and/or organizations within a defined geographic region involved in the advancement of bioinformatics. Such groups have regular meetings either in person or online, and an organizing body in the form of a board of directors or steering committee. If you are interested in affiliating your regional membership group, center, institute or network with ISCB, please review these guidelines (.pdf) and send your exploratory questions to Diane E. Kovats, ISCB Chief Executive Officer (This email address is being protected from spambots. You need JavaScript enabled to view it.). For information about the Affilliates Committee click here.
Topically-focused collaborative communities

Connect with ISCB worldwide

Environmental Sustainability Effort

ISCB is committed to creating a safe, inclusive, and equal environment for everyone

Resource library for education and training materials

Search jobs, find talent

Science at the click of the mouse, recorded talks

High-quality research devoted to computer-assisted analysis of biological data

Latest research and publications

Certifying Quality in Computational Biology Education

Latest updates from ISCB
Highlighting Society events, programs, and achievements

Celebrating scientific achievement and innovation

Honoring our distinguished researchers

Recognizing contributions and achievements
Center for science, collaboration, and training
Looking to explore while visiting Prague? Visit http://www.prague.eu/en to learn more about the many sightseeing adventures that wait you.
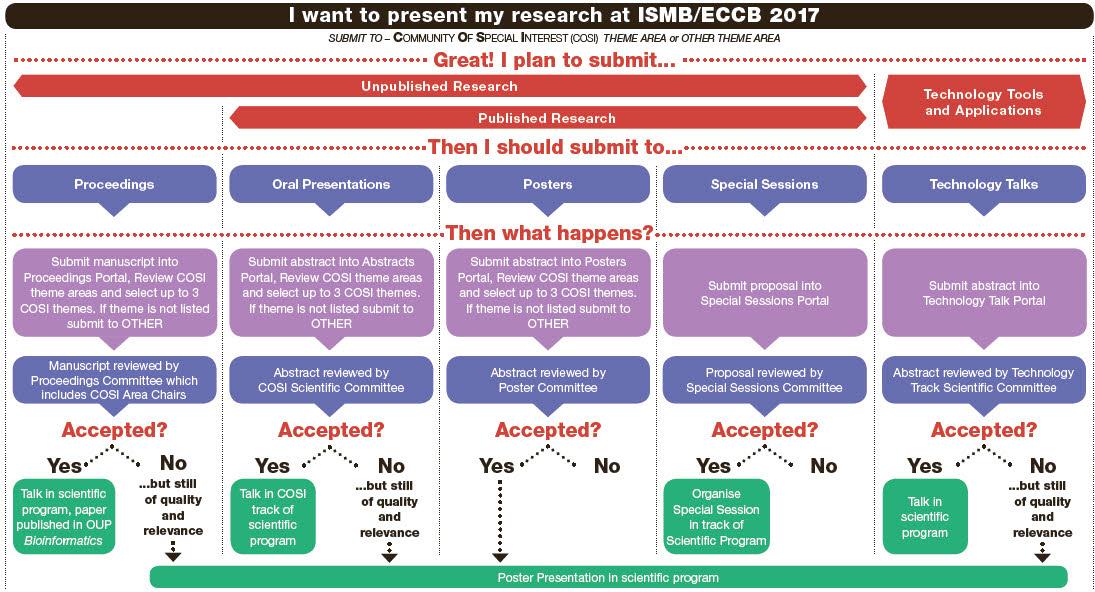
Submit Your Scientific Research for presentation at ISMB/ECCB 2017
ISCB/ECCB 2017 welcomes submissions for presentation at the conference. Select your submission areas below to learn more.
Art & Science Award
Wikipedia Award
RCSB PDB Poster Prize
F1000Research Poster Award
Ian Lawson Van Toch Memorial Award for Outstanding Student Paper
Download Award Winner's as PDF
 “Smith-Waterman Algorithm”
“Smith-Waterman Algorithm”  “Margaret Oakley Dayhoff”
“Margaret Oakley Dayhoff”  Nicole Wheeler
Nicole Wheeler 



Large-scale screenings of cancer cell lines with detailed genomic profiles against libraries of pharmacological compounds are currently being performed in order to gain a better understanding of the genetic component of drug response and to enhance our ability to predict drug sensitivity from genetic profiles. These screens differ from the clinical setting in which (1) medical records only contain the response of a patient to very few drugs, and in which (2) selecting the most promising out of all therapies is more important than accurately predicting the sensitivity to the given drug. Current regression models for drug sensitivity prediction fail to account for these two properties. We present a machine learning approach, named Kernelized Rank Learning (KRL), that ranks drugs based on their predicted effect per patient, circumventing the difficult problem of precisely predicting the sensitivity to the given drug. Our approach outperforms several state-of-the-art predictors in drug recommendation, particularly in a clinically-relevant case where few training data are available.
In biomarker research, the goal is to construct an accurate prediction rule on the basis of a small number of predictors to make it practical in the clinical setting. Such rule typically is used to determine presence of disease/malignancy, to stratify patients into subtypes or to select an optimal treatment option. Advances in high-throughput data generation have dramatically expanded the search space for biomarker discovery, making the selection of an optimal biomarker signature from large and noisy datasets challenging. In this project, we aim to benchmark the procedure of biomarker signature selection, using measurements of 35 murine strains from the BXD genetic reference strain panel [1]. Animals of each strain were respectively exposed to high-fat and chow diets [2], yielding 70 samples in total. We use 2100 liver proteins measured with SWATH-MS to predict seven metabolism-related continuous phenotypic traits: body weight, fat mass, lean mass, blood glucose and insulin levels, body temperature during the cold test, respiration volume. Some of these traits are strongly linked to liver biochemistry (fat, glucose), and some are, to our knowledge, independent (e.g. body temperature). Thus, we select biomarker signature of few proteins to predict the respective phenotype using several feature selection approaches. The ability of the model to generalize shows whether the model derived from the experiment can be ultimately translated to clinical setting. For each trait, we select best features multiple times using cross-validation. If the signatures for each sampling are similar (the signature is stable), the joint signature can be generalized to an independent population. Using various metrics, we estimate the stability of biomarker signatures for each feature selection approach. We show that the stability of the signature heavily depends on the relevance of the molecular profile to the phenotype it aims to predict. For our dataset, biomarker signature derived from liver proteome is stable for fat mass and glucose level, which are traits related to liver metabolism, and is highly unstable for body temperature. Thus, stability can be used to assess whether the biomarker signature is in principle identifiable from the given dataset.
Art in Science
BD2K Special Track
ELIXIR Special Track
Birds of a Feather
CoBE COSI
COSI Tracks & Other Abstracts
ISCB Town Hall
Keynotes
Posters
Industry Posters
Proceedings
Schedule Overview
Social Events
Special Sessions
Student Council Symposium
Technology Track
Tutorials
Workshops
 CRC Press, part of the Taylor and Francis Group, is the premier publisher of references, textbooks and ebooks in computational biology, systems biology and bioinformatics. Stop by our booth to view our latest and bestselling titles, and to take advantage of our conference discount. If you are interested in writing or editing a book for our renowned series in mathematical and computational biology, visit our booth to chat with our editors.
CRC Press, part of the Taylor and Francis Group, is the premier publisher of references, textbooks and ebooks in computational biology, systems biology and bioinformatics. Stop by our booth to view our latest and bestselling titles, and to take advantage of our conference discount. If you are interested in writing or editing a book for our renowned series in mathematical and computational biology, visit our booth to chat with our editors.

At the European Bioinformatics Institute (EMBL-EBI), we help scientists realise the potential of ‘big data’ in biology, helping them exploit complex information to make discoveries that benefit mankind. We manage the world’s public biological data and make it freely available to the scientific community via a range of services and tools, perform basic research and provide professional training in bioinformatics. We are part of the European Molecular Biology Laboratory (EMBL), a non-profit, intergovernmental organisation funded by 21 member states and two associate member states. Our 570 staff represent 57 nationalities, and we welcome a regular stream of visiting scientists throughout the year. We are located on the Wellcome Genome Campus in Hinxton, Cambridge in the United Kingdom.

BioExcel is an EU funded Centre of Excellence for provision of support to academic and industrial researchers in the use of high-performance computing (HPC) and high-throughput computing (HTC) in computational biomolecular research.

Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide.

Genomics, Proteomics & Bioinformatics (GPB) is one of ISCB’s Journals of Interest. As the official journal of Beijing Institute of Genomics, Chinese Academy of Sciences and Genetics Society of China, GPB is hosted by Elsevier as a gold open-access journal and publishes high-quality articles on omics and bioinformatics worldwide.

Looking to publish your research? Discover Springer’s print and electronic publication services, including Open Access! Get high-quality review, maximum readership and rapid distribution. Visit our booth or springer.com/authors. You can also browse key titles in your field and buy (e)books at discount prices. With Springer you are in good company.
 The Royal Society journals offer rigorous, constructive peer review; open access options; promotion by a dedicated press office; and broad dissemination to an international audience. To find out more, please visit the Royal Society Publishing booth where Dr Tim Holt will be happy to answer your questions. Alternatively, visit our website at http://royalsociety.org/journals
The Royal Society journals offer rigorous, constructive peer review; open access options; promotion by a dedicated press office; and broad dissemination to an international audience. To find out more, please visit the Royal Society Publishing booth where Dr Tim Holt will be happy to answer your questions. Alternatively, visit our website at http://royalsociety.org/journals
 Big Data to Knowledge (BD2K) is a trans-NIH initiative established to enable biomedical
research as a digital research enterprise, to facilitate discovery and support new knowledge,
and to maximize community engagement. The BD2KCCC aims to sustain the impact of BD2K
achievement within the global biomedical community and the public domain through
innovative solutions in resource indexing and knowledge management.
Big Data to Knowledge (BD2K) is a trans-NIH initiative established to enable biomedical
research as a digital research enterprise, to facilitate discovery and support new knowledge,
and to maximize community engagement. The BD2KCCC aims to sustain the impact of BD2K
achievement within the global biomedical community and the public domain through
innovative solutions in resource indexing and knowledge management.
 Founded in 2012 and with over 500,000 registered users, Overleaf is an academic authorship tool that allows seamless collaboration and effortless manuscript submission, all underpinned by cloud-technology. By providing an intuitive online collaborative writing and publishing platform, Overleaf is making the process of writing, editing and publishing scientific documents quicker and easier.
Founded in 2012 and with over 500,000 registered users, Overleaf is an academic authorship tool that allows seamless collaboration and effortless manuscript submission, all underpinned by cloud-technology. By providing an intuitive online collaborative writing and publishing platform, Overleaf is making the process of writing, editing and publishing scientific documents quicker and easier.

The sbv IMPROVER project (www.sbvimprover.com), funded by Philip Morris International, was created to verify systems biology data, methods, and conclusions.
Computational challenges leveraging the wisdom of the crowd allow to benchmark methods for specific tasks, such as signature extraction. Four challenges have already been successfully conducted and confirmed that the aggregation of predictions often leads to better results than individual predictions.
Whenever the scientific question of interest does not have a gold standard, but may greatly benefit from the scientific community to come together and discuss their approaches and results, datathons are set up.
 DNAstack develops a cloud-based platform for genomics data analysis and sharing.
DNAstack develops a cloud-based platform for genomics data analysis and sharing.
The ERC is the first European funding organisation for excellent frontier research. Every year, it selects and funds the very best, creative researchers of any nationality and age, to run projects based in the EU. The ERC has a budget of over €13 billion for the years 2014 to 2020.

Cambridge University Press dates from 1534 and is part of the University of Cambridge. Our mission is to unlock people's potential with the best learning and research solutions by combining state-of-the-art content with the highest standards of scholarship, writing and production. Visit our stand for 20% off all titles on display.

The Global Organisation for Bioinformatics Learning, Education and Training, is a not-for-profit foundation that seeks to unite, inspire and equip bioinformatics trainers worldwide. GOBLET seeks to achieve this by cultivating the global bioinformatics trainer community, setting standards and providing high-quality resources to support bioinformatics training.
 PLOS (Public Library of Science) is a nonprofit Open Access publisher, innovator and advocacy organization dedicated to accelerating progress in science and medicine by leading a transformation in research communication. The PLOS suite of influential journals contain rigorously peer-reviewed Open Access research articles from all areas of science and medicine.
PLOS (Public Library of Science) is a nonprofit Open Access publisher, innovator and advocacy organization dedicated to accelerating progress in science and medicine by leading a transformation in research communication. The PLOS suite of influential journals contain rigorously peer-reviewed Open Access research articles from all areas of science and medicine.
Web Address: https://www.plos.org

NDEx, the Network Data Exchange, is a collaborative software infrastructure for storing, sharing and publishing biological network knowledge. The NDEx Project maintains a free, public website and is developed in close collaboration with the Cytoscape team and the Ideker laboratory at UC San Diego.

The Jalview project develops free software for the the interactive generation, analysis, editing and visualisation of biological sequence alignments. Jalview integrates with Chimera molecular graphics software, the PDBe services and JPred4 structure predictor. The project provides training at all levels as well as collaborative development opportunities.

"Bioinformatics Algorithms" courses on Coursera, created at the University of California, San Diego by Phillip Compeau and Pavel Pevzner.
 The Hyve is an international fast growing company, providing professional services in translational bioinformatics and medical informatics research and development. The Hyve builds on existing open source software, bringing the innovation from the academic community to enterprise application in pharma and healthcare. Services include software development, data curation and consultancy.
The Hyve is an international fast growing company, providing professional services in translational bioinformatics and medical informatics research and development. The Hyve builds on existing open source software, bringing the innovation from the academic community to enterprise application in pharma and healthcare. Services include software development, data curation and consultancy.
 Elsevier is a world-leading provider of information solutions that enhance the performance of science, health, and technology professionals, empowering them to make better decisions, and deliver better care.
Elsevier is a world-leading provider of information solutions that enhance the performance of science, health, and technology professionals, empowering them to make better decisions, and deliver better care.

ENPICOM is a data analysis software and cloud solutions company for biotech and agritech. We do the heavy lifting, so you can do the thinking. We work with academic and industrial partners to research and develop novel immunotherapies and cancer vaccines, by providing innovative software solutions for immunogenomics.
ENPICOM's leading product, ImmunoGenomiX, contains tools for immune repertoire sequencing and cross-reactivity analysis of affinity-enhanced TCR to prevent off-target and organ-specific toxicities.
F1000Research is an Open Science publishing platform offering rapid publication of posters, slides and articles with no editorial bias. All articles benefit from transparent peer review and the inclusion of all source data.
![]()
ELIXIR is an intergovernmental organisation that brings together life science resources from across Europe. These resources include databases, software tools, training materials, cloud storage and supercomputers. The goal of ELIXIR is to coordinate these resources so that they form a single infrastructure. This infrastructure makes it easier for scientists to find and share data, exchange expertise, and agree on best practices. Ultimately, it will help them gain new insights into how living organisms work. ELIXIR includes 21 members and over 180 research organisations.
![]() The International Society for Computational Biology (ISCB) (www.iscb.org) was the first and continues to be the only society representing computational biology and bioinformatics worldwide. ISCB serves a global community of nearly 3,400 scientists dedicated to advancing the scientific understanding of living systems through computation by:
The International Society for Computational Biology (ISCB) (www.iscb.org) was the first and continues to be the only society representing computational biology and bioinformatics worldwide. ISCB serves a global community of nearly 3,400 scientists dedicated to advancing the scientific understanding of living systems through computation by:
ISCB has three official journals – OUP Bioinformatics, PLOS Computational Biology and F1000Research ISCB Community Journal, and has affiliations in place with several other publications for the benefit of our members.

ISCB Student Council (SC, www.iscbsc.org) is an international network of young researchers in the broader disciplines of the field of Computational Biology. SC provides opportunities for networking, career enhancement and skills development for the next generation of Computational Biology leaders. The SC Symposium (symposium.iscbsc.org) is organized as a part of the annual ISMB conference with student presentations, keynotes, panel discussions and a poster session. Come visit our friendly SC representatives at the booth for more information.
 http://eccb.iscb.org/
http://eccb.iscb.org/
ECCB 2018 is the key European computational biology event in 2018 gathering scientists working at the intersection of a broad range of disciplines including computer science, mathematics, biology, and medicine. Participation at ECCB 2018 will be the prime opportunity to keep pace with cutting-edge research in such exciting topics, and to network with other members of our community. ECCB 2018 is the 17th edition of the ECCB conference series, which in 2018 will take place in Athens Greece.

A non-profit biomedical research institution where mathematics and computer science are applied to the study of genomics, epigenetics, systems biology, biological image analysis, and structural & chemical biology. Our high-performance computing facility allows seamless integration of computational scientists with experimentalists. Visit our booth to discuss postdoctoral fellowship opportunities.

The Jackson Laboratory is recruiting outstanding Postdoctoral Associates for our expanding research campuses in Bar Harbor, Maine, and Farmington, Conn. Join our team and contribute to our important mission of discovering precise genomic solutions for disease and empowering the global biomedical community in our shared quest to improve human health.
Ishwar Chandramouliswaran, NIH NIAID, United States
Susan Gregurick, NIH NIGMS, United States
Harry Caufield, University of California Los Angeles, United States
Jiawei Han, University of Illinois at Urbana-Champaign, United States
Peipei Ping, University of California Los Angeles, United States
Wei Wang, University of California Los Angeles, United States
Big Data to Knowledge (BD2K) is a trans-NIH initiative established to enable biomedical research as a digital research enterprise, to facilitate discovery and support new knowledge, and to maximize community engagement. Since its inception in October 2014, the BD2K program has been involved in the production of more than 546 publications and 148 software platforms, with impact in the fields of annotation, data management, metadata standards, data integration, personalized real-world monitoring, predictive models, causal analytics, and precision medicine. BD2K Centers continue to forge new advances in the specific applications of tools to propel our understanding of disease and biological pathways.
The overall focus of this track parallels the BD2K program’s objectives: to facilitate broad use of biomedical digital assets by making them Findable, Accessible, Interoperable, and Reusable (FAIR), to conduct research and develop the methods, software, and tools needed to analyze biomedical Big Data, to enhance training in the development and use of methods and tools necessary for biomedical Big Data, and to support a data ecosystem that accelerates discovery as part of a digital enterprise. Two sessions of talks will focus on addressing these objectives in the fields of machine learning and in metadata and indexing. A third session will then address topics and emerging technologies in data science, open science, and their relationship to the NIH Commons. The track will conclude with a panel session to assist discussions about ongoing questions in biomedical research and data science.
| Time | Event | Speakers |
|---|---|---|
| 10:00 - 11:00 | Keynote | Chair: Ishwar Chandramouliswaran |
| 10:00 - 10:30 | Introduction and Overview of BD2K | Susan Gregurick (NIH NIGMS) |
| 10:30 - 11:00 | Keynote Talk:“Data Commons in the age of Precision Medicine” | Warren Kibbe (NIH NCI) |
| 11:00 - 12:30 | Session 1: Machine Learning | Chairs: Jiawei Han and Harry Caufield |
| 11:00 - 11:15 | Machine Learning speaker 1 “Learning to Uncover Host-Virus Interactions” | Mark Craven (U Wisconsin - Madison) |
| 11:15 - 11:30 | Machine Learning speaker 2 “Genome-guided Framework for Personalized Cancer Treatment” | Krishna Kalari (Mayo Clinic) |
| 11:30 - 11:45 | Machine Learning speaker 3 “Construction of Biological Networks from Massive Text Data: A Data-Driven Approach” | Jiawei Han(UIUC) |
| 11:45 - 12:00 | Machine Learning speaker 4 “Decoding genome structure” | Jian Ma(Carnegie Mellon U) |
| 12:00 - 12:15 | Machine Learning speaker 5 “Aztec: A machine learning empowered platform for FAIR biomedical software” | Wei Wang(UCLA) |
| 12:15 - 12:30 | Machine Learning speaker 6 “KnowEnG: Knowledge Network-guided analysis of genomics data on the Cloud” | Saurabh Sinha(UIUC) |
| 12:30 - 2:00 | Scheduled break (Lunch & ISMB poster session) | |
| 2:00 - 4:00 | Session 2: Metadata and Indexing | Chair: Mark Musen |
| 2:00 - 2:20 | Metadata and Indexing speaker 1 “CEDAR: Technology for using metadata standards to ease sharing, integration, and reuse of biomedical data” | Mark Musen (Stanford) |
| 2:20 - 2:40 | Metadata and Indexing speaker 2 “OmicsDI - Discovery and Connectivity Analysis of Omics Datasets” | Henning Hermjakob (EMBL-EBI) |
| 2:40 - 3:00 | Metadata and Indexing speaker 3 “Going FAIR: where are we?” | Susanna-Assunta Sansone (Oxford) |
| 3:00 - 3:20 | Metadata and Indexing speaker 4 "To be FAIR, we should give Ontologies and Data Visualization a try.” | Nils Gehlenborg (Harvard) |
| 3:20 - 3:40 | Metadata and Indexing speaker 5 “Open Neuroimaging Laboratory and BrainBox” | Roberto Toro (Institut Pasteur) |
| 3:40 - 4:00 | Metadata and Indexing speaker 6 "Inferring and explaining gene-disease associations through implicit knowledge" | Kristina Hettne (Leiden University Medical Ctr) |
| 4:00 - 4:30 | Scheduled break | |
| 4:30 - 6:00 | Session 3: Data Science, Open Science, and the Commons | Chair: Peipei Ping |
| 4:30 - 4:45 | Data Science/Open Science speaker 1 “Opportunities for Data Intensive Research in Infectious Diseases” | Maria Giovanni (NIH NIAID) |
| 4:45 - 5:00 | Data Science/Open Science speaker 2 “The NCI Cancer Research Data Commons” | Anthony Kerlavage(NIH NCI) |
| 5:00 - 5:15 | Data Science/Open Science speaker 3 | Aurora Blucher (OHSU) |
| 5:15 - 5:30 | Session 2: Data Science/Open Science speaker 4 “Accelerating Research on the Cloud” | Angel Pizarro (Amazon Web Services) |
| 5:30 - 6:00 | Panel Discussion | |

ISCB Members enjoy discounts on conference registration (up to $150), journal subscriptions, book (25% off), and job center postings (free).

Connecting, Collaborating, Training, the Lifeblood of Science. ISCB, the professional society for computational biology!

Giving never felt so good! Considering donating today.
![]()
